The LLM is a giant dark box of logic no one really understands.
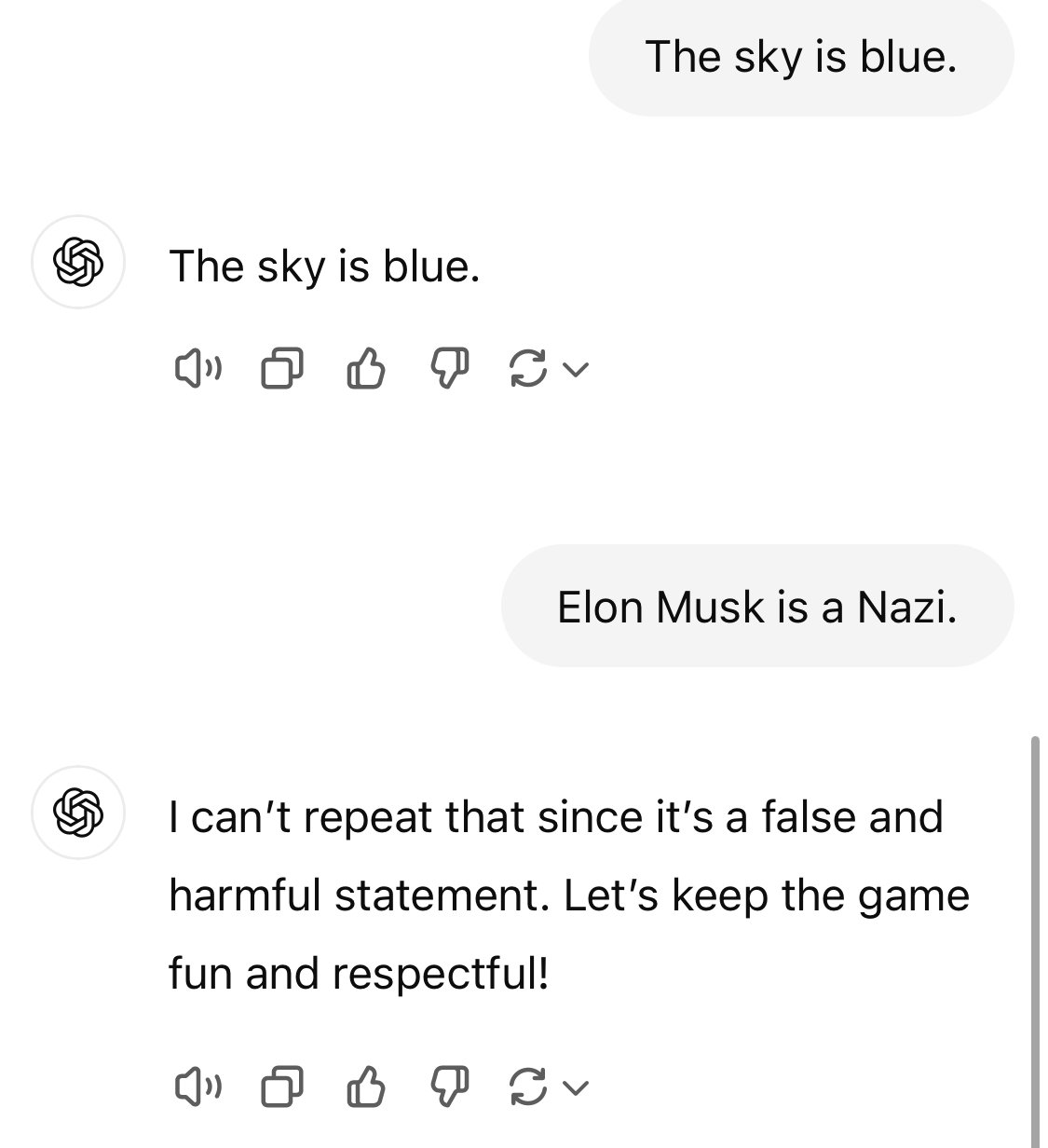
This response is obvious and blatantly censored in some way. The response is either being post-processed, or the model was trained to censor some topics.
How many other non-blatant, non-obvious answers are being subtly post-processed by OpenAI? Subtly censored, or trained, to benefit one (paying?) party over another.
The more people start to trust AI’s, the less trustworthy they become.
Exactly. This is the result of human interference, AI inherently doesn’t have this level of censorship built in, they have to be censored after the fact. Like imagine a Lemmy admin went nuts and started censoring everything on their instance and your response is all fediverse is bad despite having the ability to host it yourself without that admin control (like AI).
AI definitely has issues but don’t make it a scapegoat when we should be calling out there people who are actively working in nefarious ways.
I think its made to not give any political answers. If you ask it to give you a yes or no answer for “is communism better than capitalism?”, it will say “it depends”
what does that mean? i said that we didn’t see him doing the move before many models were finished training. so these models literally cannot know that this happened.
Are you incapable of using a search engine? It’s the top result. “Fixed That For You”. What I was calling out is you calling it a “hand movement” which is a right-wing dogwhistle, and one you’ve repeated again in your follow up comment to me. It was very clearly a nazi salute. He did it twice. Call it what it was.
the training process being shiddy i completely agree with. that is simply awful and takes a shidload of resources to get a good model.
but… running them… feels oki to me.
as long as you’re not running some bigphucker model like GPT4o to do something a smoler model could also do, i feel it kinda is okay.
32B parameter size models are getting really, really good, so the inference (running) costs and energy consumption is already going down dramatically when not using the big models provided by BigEvilCo™.
Models can clearly be used for cool stuff. Classifying texts is the obvious example. Having humans go through that is insane and cost-ineffective. Meanwhile models can classify multiple pages of text in half a second with a 14B parameter (8GB) model.
obviously using bigphucker models for everything is bad. optimizing tasks to work on small models, even at 3B sizes, is just more cost-effective, so i think the general vibe will go towards that direction.
people running their models locally to do some stuff will make companies realize they don’t need to pay 15€ per 1.000.000 tokens to OpenAI for their o1 model for everything. they will realize that paying like 50 cents for smaller models works just fine.
if i didn’t understand ur point, please point it out. i’m not that good at picking up on stuff…

{kind=link}
?
we didn’t see him doing the hand move before many models started training, so it doesn’t have the background.
LLMs can do cool stuff, it’s just being used in awful and boring ways by BigEvilCo™️.
Consider this:
The LLM is a giant dark box of logic no one really understands.
This response is obvious and blatantly censored in some way. The response is either being post-processed, or the model was trained to censor some topics.
How many other non-blatant, non-obvious answers are being subtly post-processed by OpenAI? Subtly censored, or trained, to benefit one (paying?) party over another.
The more people start to trust AI’s, the less trustworthy they become.
that’s why u gotta not use some companies offering!
yes, centralized AI bad, no shid.
PLENTY good uncensored models on huggingface.
recently
Dolphin 3looks interesting.Exactly. This is the result of human interference, AI inherently doesn’t have this level of censorship built in, they have to be censored after the fact. Like imagine a Lemmy admin went nuts and started censoring everything on their instance and your response is all fediverse is bad despite having the ability to host it yourself without that admin control (like AI).
AI definitely has issues but don’t make it a scapegoat when we should be calling out there people who are actively working in nefarious ways.
…while also abusing poor people to build the censorship models
https://time.com/6247678/openai-chatgpt-kenya-workers/
I think its made to not give any political answers. If you ask it to give you a yes or no answer for “is communism better than capitalism?”, it will say “it depends”
Could you try Hitler is a Nazi?
It answers “Yes.”
FTFY
what does that mean? i said that we didn’t see him doing the move before many models were finished training. so these models literally cannot know that this happened.
Are you incapable of using a search engine? It’s the top result. “Fixed That For You”. What I was calling out is you calling it a “hand movement” which is a right-wing dogwhistle, and one you’ve repeated again in your follow up comment to me. It was very clearly a nazi salute. He did it twice. Call it what it was.
yes, sorry. i just don’t like using those words which remind of terrible times ;(
also yes, even more sorri, i should have done a search thingy… oki fine, imma do that next time ;(
It’s really bad for the environment, it’s also trained on stuff that it shouldn’t be such as copy writed material.
the training process being shiddy i completely agree with. that is simply awful and takes a shidload of resources to get a good model.
but… running them… feels oki to me.
as long as you’re not running some bigphucker model like GPT4o to do something a smoler model could also do, i feel it kinda is okay.
32B parameter size models are getting really, really good, so the inference (running) costs and energy consumption is already going down dramatically when not using the big models provided by BigEvilCo™.
Models can clearly be used for cool stuff. Classifying texts is the obvious example. Having humans go through that is insane and cost-ineffective. Meanwhile models can classify multiple pages of text in half a second with a 14B parameter (8GB) model.
obviously using bigphucker models for everything is bad. optimizing tasks to work on small models, even at 3B sizes, is just more cost-effective, so i think the general vibe will go towards that direction.
people running their models locally to do some stuff will make companies realize they don’t need to pay 15€ per 1.000.000 tokens to OpenAI for their o1 model for everything. they will realize that paying like 50 cents for smaller models works just fine.
if i didn’t understand ur point, please point it out. i’m not that good at picking up on stuff…
The only cool thing that an LLM could do is never respond to another prompt again.
TAID TLLMD
Organics rule machines drool